데이터베이스 복제하기(리플리케이션) 2 - 테코와 알아보는 대규모 데이터 관리



테코의 고민 2 - 이벤트에 어떤 내용을 기록해야 해?
GTID 기반의 안정적인 복제 방식을 도입한 후 잘 운영되는 카페를 보며 행복한 나날을 보내는 테코.
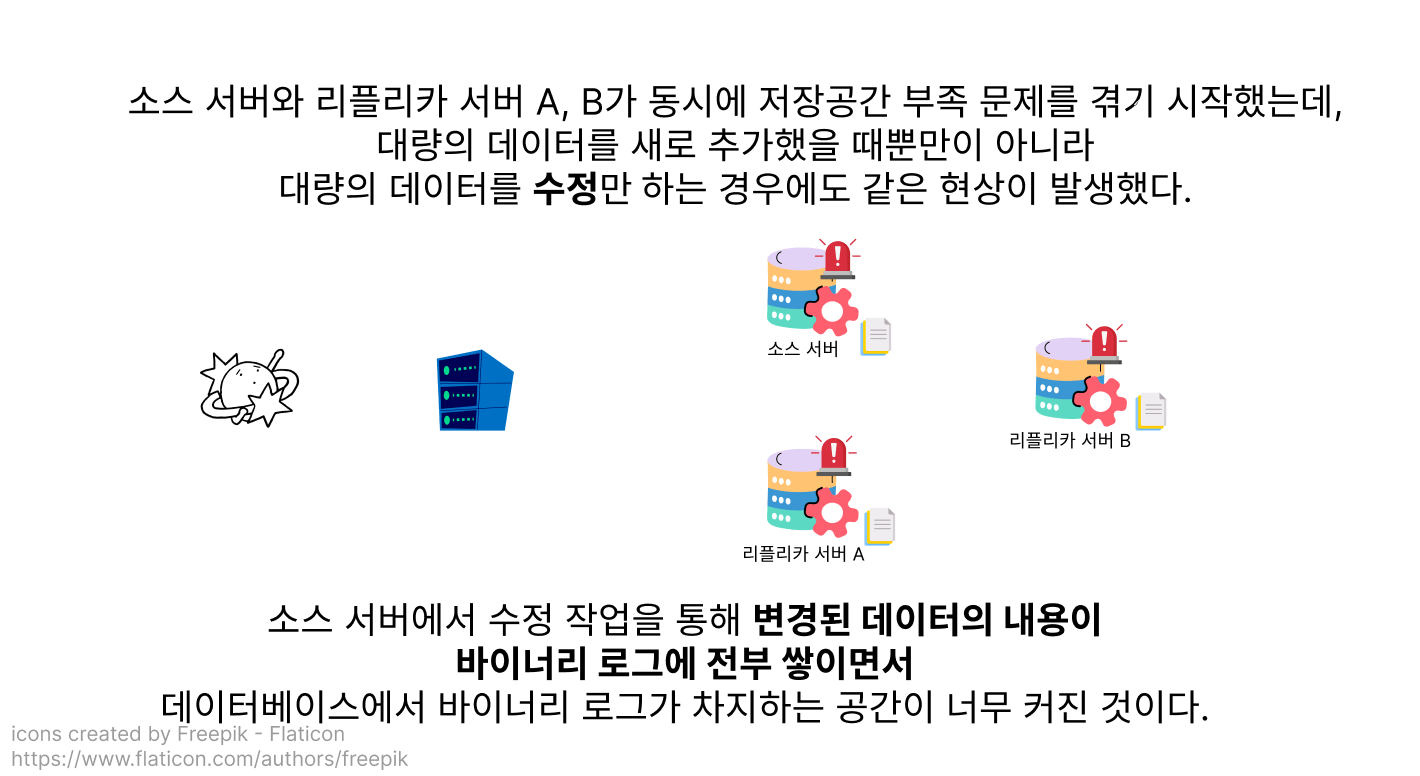
그런데 어느 날, 데이터베이스에 저장된 회원 데이터를 전체적으로 업데이트하는 작업을 하던 도중
데이터베이스의 소스 서버와 리플리카 서버 A, 리플리카 서버 B는 데이터베이스의 여유 공간이 부족하다는 경고를 차례대로 보내왔어요.
데이터를 수정만 했지, 한꺼번에 대량으로 추가하는 작업은 하지 않았기 때문에 매우 의아해하던 테코는 그 원인이 바이너리 로그에 있음을 알아차리고 깊은 고민에 빠졌어요.
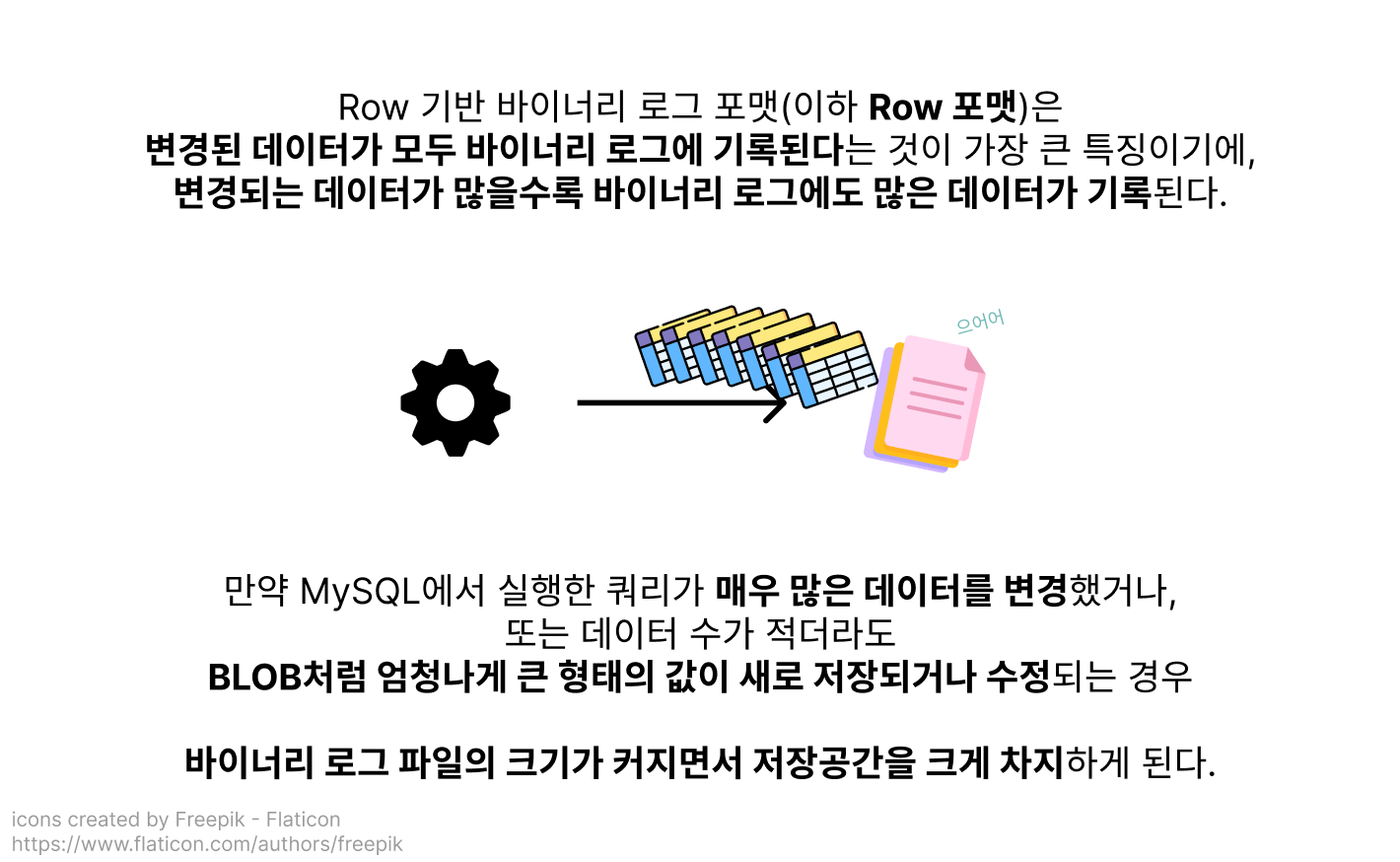
변경된 데이터를 기록한다면 - Row 포맷
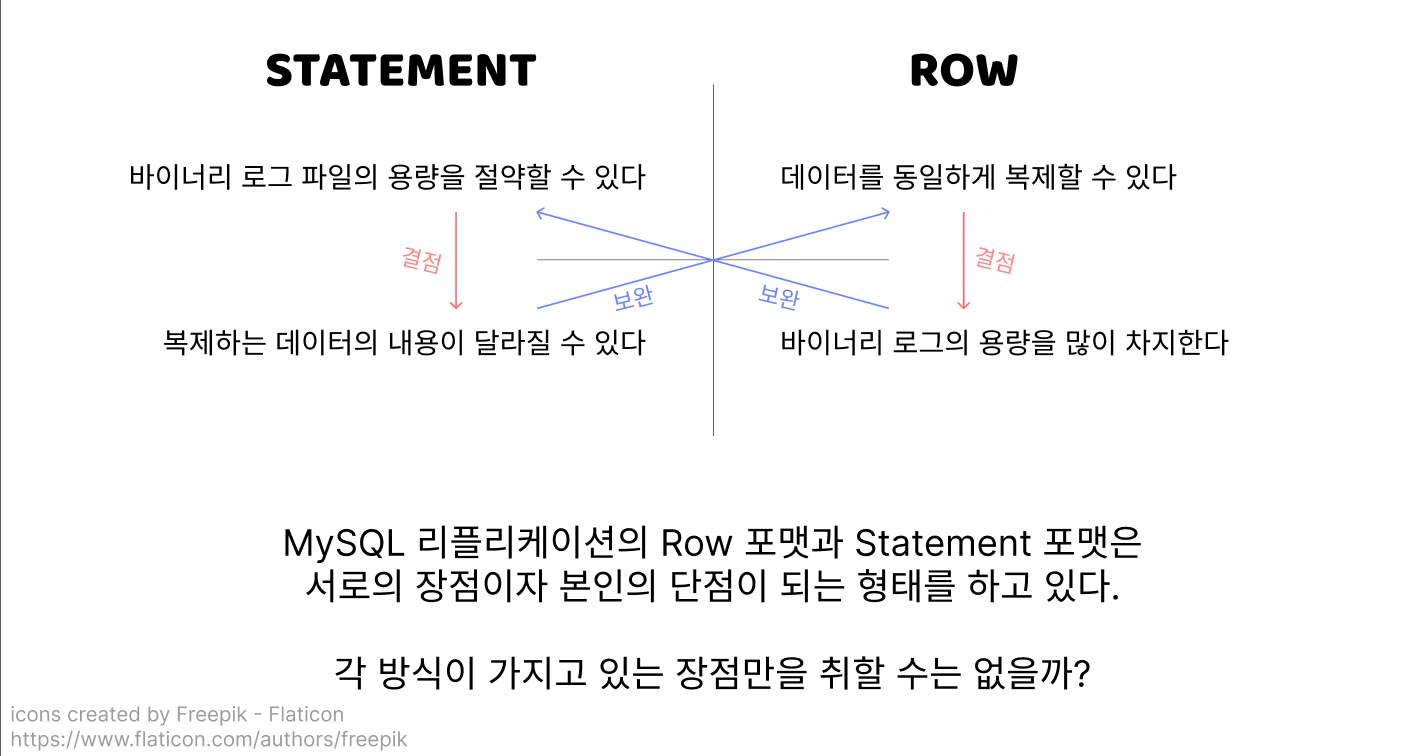
테코네 서버의 데이터베이스는 바이너리 로그의 각 이벤트를 Row 포맷으로 기록하고 있었는데, 변경된 데이터를 그대로 바이너리 로그에 등록하는 특성상 매우 많은 데이터를 변경한 경우 그 대량의 데이터들이 전부 로그에 기록되면서 데이터베이스 공간에 과부하를 줄 수 있다는 문제가 있음을 알게 되었어요.

그렇다면 변경된 데이터를 그대로 바이너리 로그에 기록하는 대신 다른 방법을 쓸 수는 없을까. 차라리 실행한 SQL을 기록하는 게 낫지 않을까?
실행한 SQL을 기록한다면 - Statement 포맷

각 이벤트에서 실행한 SQL 문을 바이너리 로그에 기록하는 Statement 기반 바이너리 로그 포맷을 도입한다면 바이너리 로그의 용량이 크게 줄어들기 때문에 더 이상 용량 걱정을 하지 않아도 될 거예요.
하지만 Statement 포맷을 선뜻 적용하기에는 찝찝함이 느껴집니다.
SQL 문이 동일하다고 해도, 실행할 때마다 결과가 다르게 나타나는 몇몇 비 확정적(Non-Deterministic) 쿼리들이 있다면 소스 서버와 리플리카 서버의 데이터가 다르게 기록되는 정합성 문제가 일어날 수 있기 때문이었는데요!

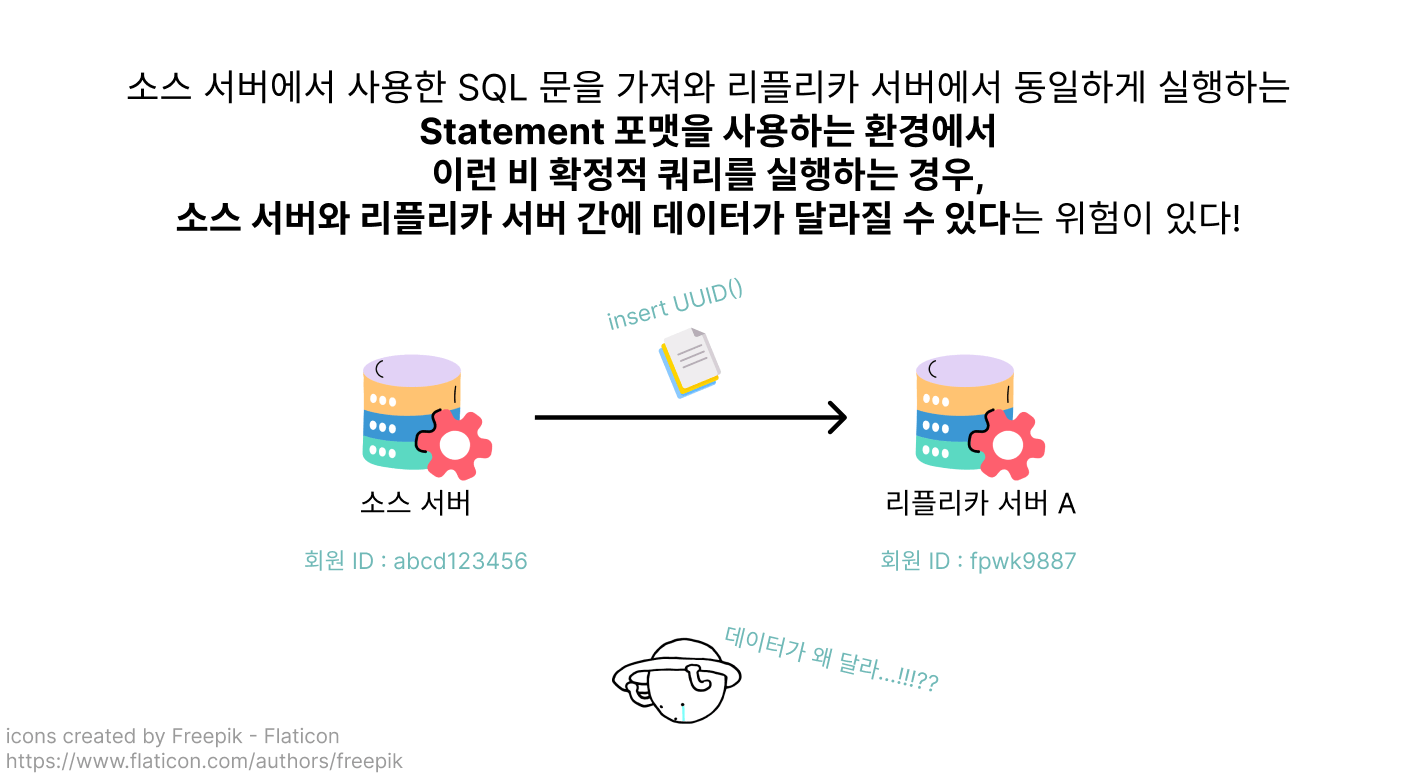
Statement 포맷을 사용하게 된다면 데이터베이스의 저장 공간을 취하는 대신 데이터 정합성이 깨진다는 딜레마에 빠지고 만 테코.
데이터를 동일하고 안전하게 복제하면서도 바이너리 로그의 크기를 적당하게 유지할 수 있는 좋은 방법은 없을까요? 🥹
두 방법의 장점만 취할 수 있다면 - Mixed 포맷
이런 고민을 MySQL 개발자들도 당연히 했을 것!
테코가 겪고 있는 딜레마를 해소해 주기 위해 MySQL에서는 평소에는 Statement 포맷으로 기록하다가, 만약 Statement 포맷으로 복제했을 때 문제가 될 가능성이 있는 쿼리인 경우에는 Row 포맷으로 변환하여 기록해주는 Mixed 포맷을 제공하고 있습니다.
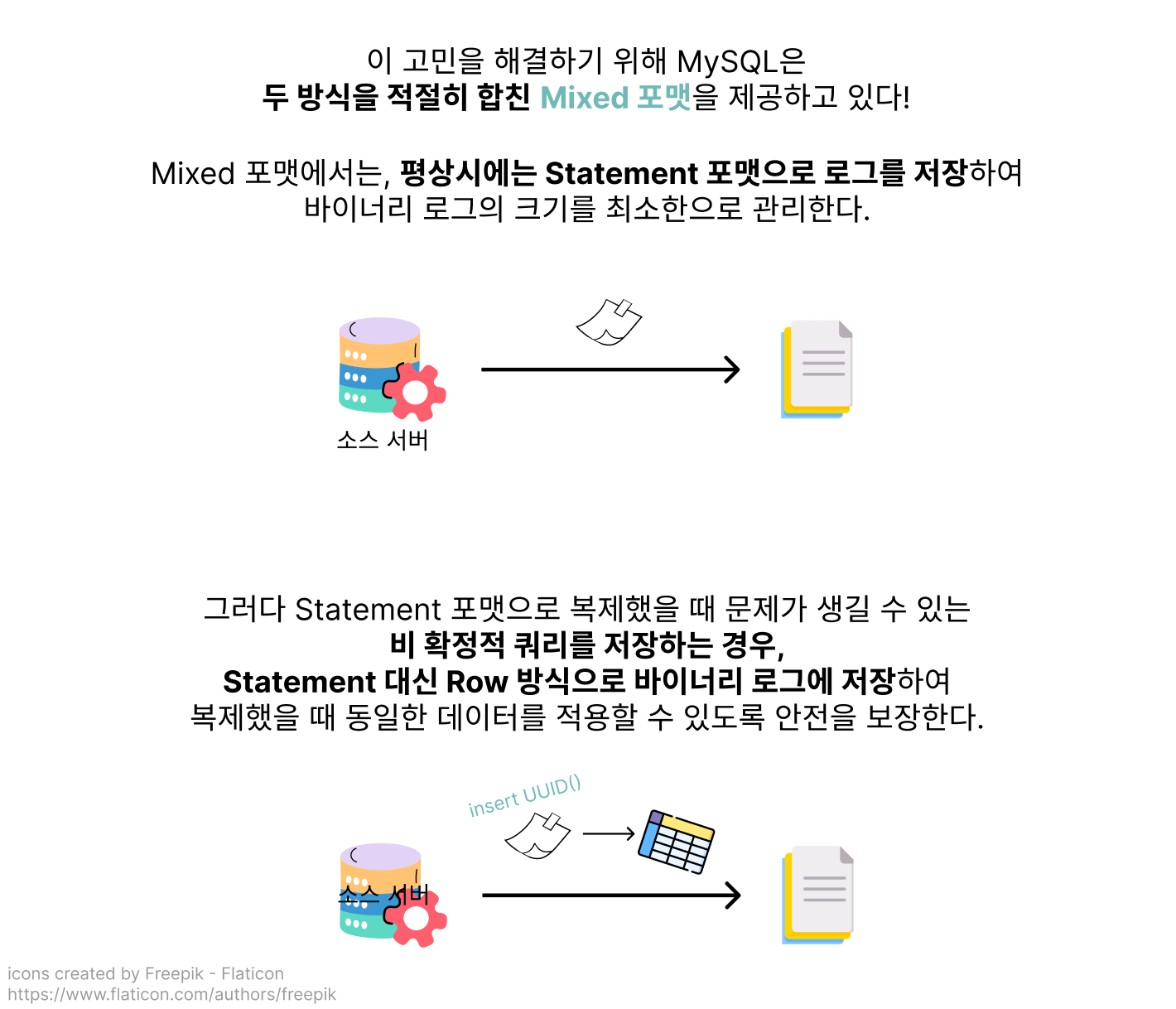

Mixed 포맷을 적용함으로써 바이너리 로그의 용량과 데이터 정합성을 성공적으로 지켜낸 테코!
시행착오를 겪으면서 많은 공부와 성장을 해내고 있습니다.
요약
- MySQL 리플리케이션의 복제 데이터 포맷
- Row 기반 바이너리 로그 포맷
- Statement 기반 바이너리 로그 포맷
- Mixed 포맷
- 자료 Real MySQL 8.0 2권 469p ~ 485p
테코의 고민 3 - 복제하는 동안 데이터에 차이가 있지 않을까
데이터의 리플리케이션을 처음 경험하는 테코는 이런 고민을 하기도 했습니다. ‘소스 서버에서 리플리카 서버로 데이터를 복제하는 데에도 시간이 걸리잖아. 복제하는 동안은 두 서버 사이의 데이터가 다를 텐데, 문제가 되지는 않을까?’
비동기
이런 고민이 들 만도 한 것이, 테코네 카페의 데이터베이스 리플리케이션은 비동기 복제(Asynchronous replication) 방식으로 동작하고 있었기 때문인데요!
이름에서 유추할 수 있듯, 소스 서버의 이벤트가 리플리카 서버들에게 잘 전송되었는지 확인하지 않기 때문에 서버들 간 데이터에 차이가 생길 가능성이 있습니다.

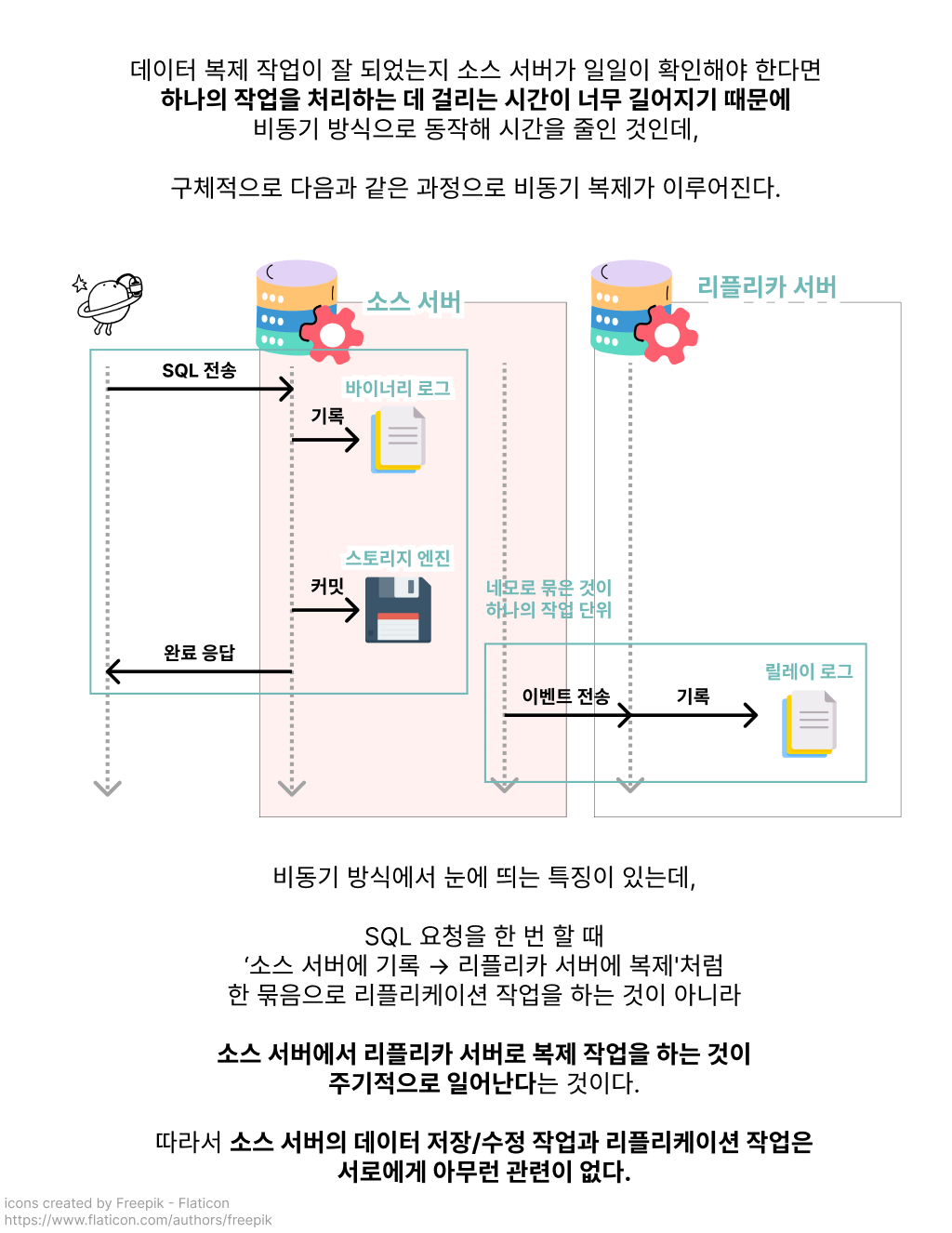


비동기 방식의 리플리케이션을 계속하기에는 찜찜한 테코. ‘동기 방식’ 같은 더 안전한 동기화 방법은 없을까 찾아보던 중 웃긴 이름의 동기화 방식을 알게 되었습니다.
‘반’동기
반동기(Semi-synchronous replication). 특이한 이름입니다. 왜 반만 동기일까요?

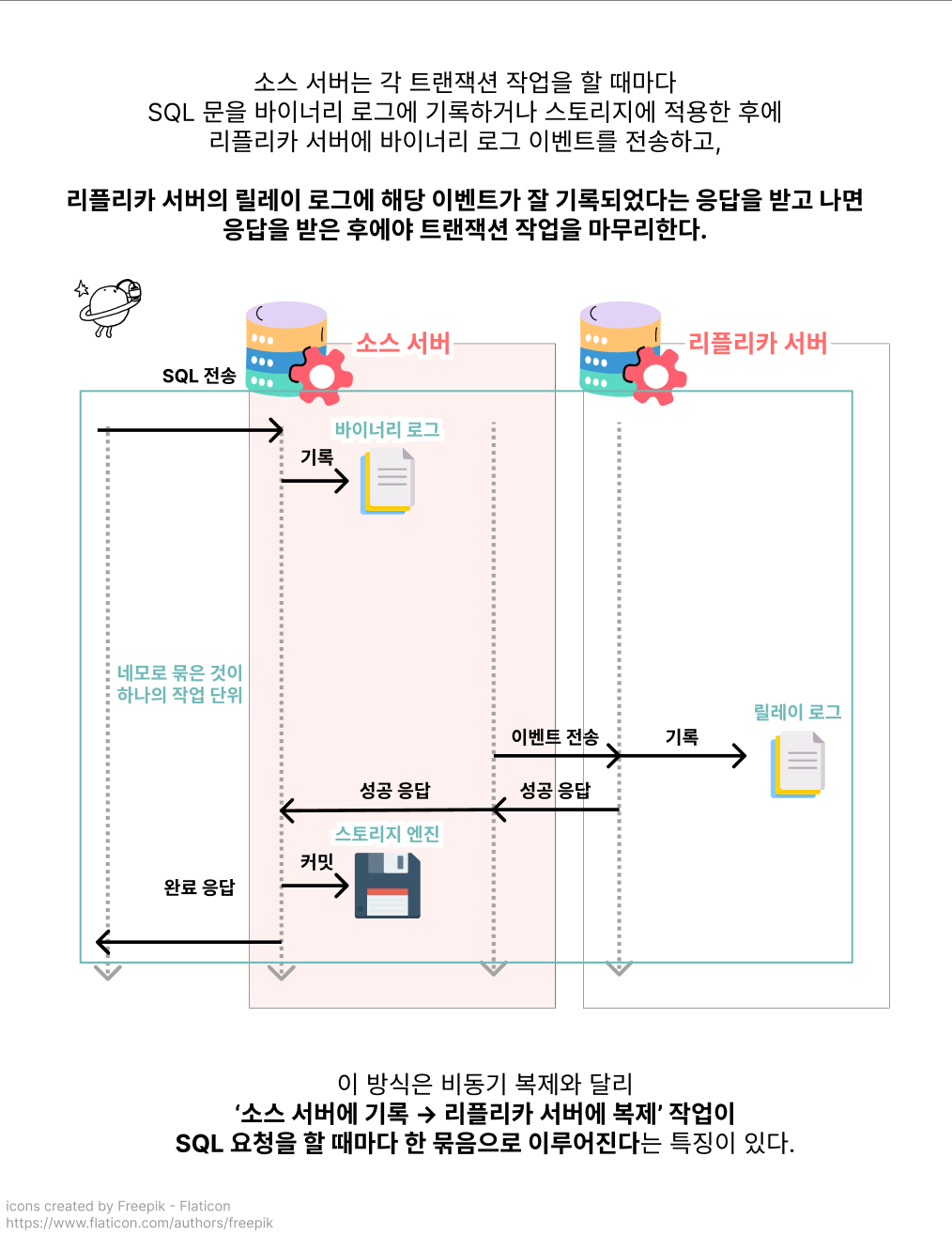
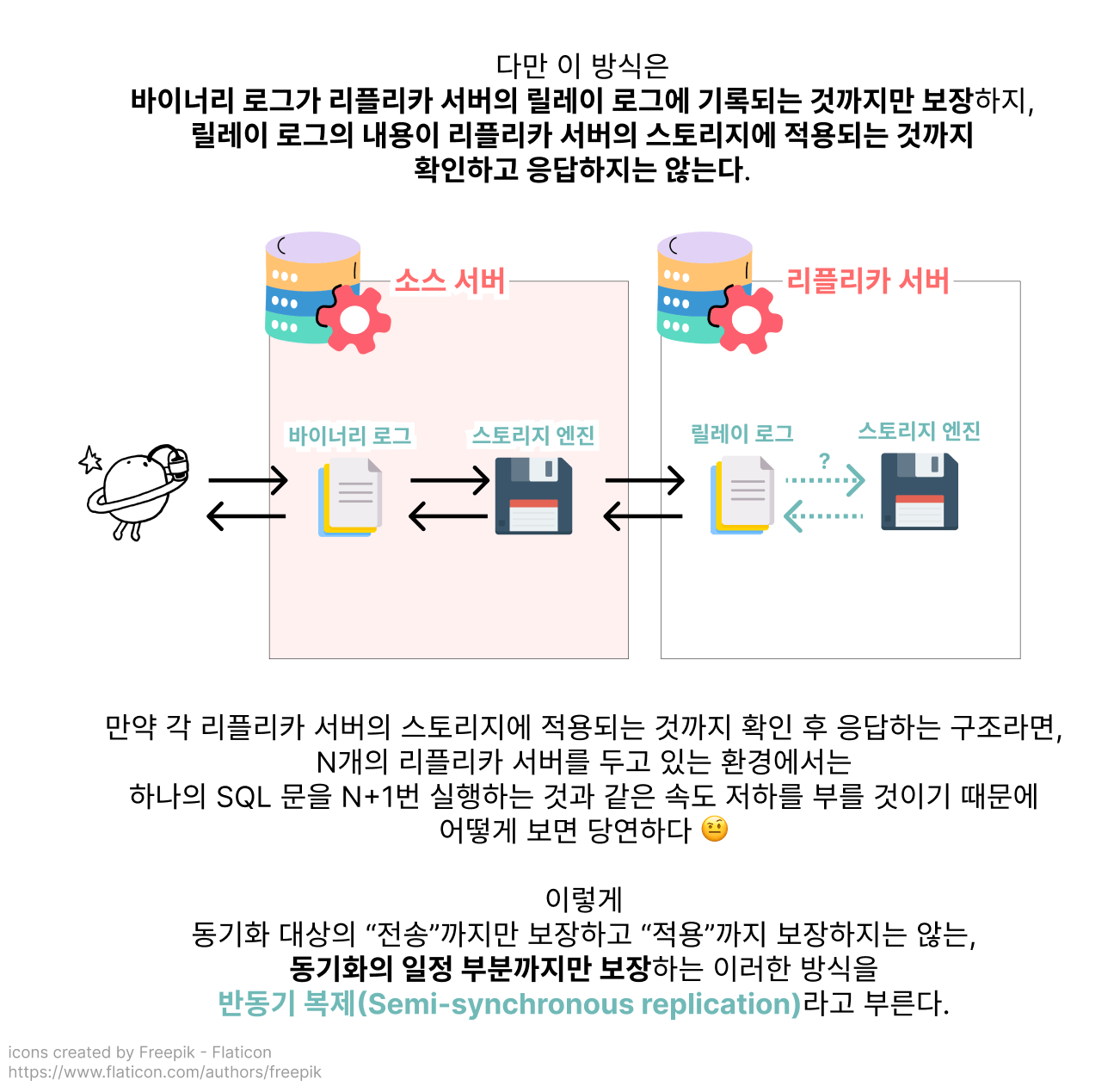
비동기 복제 대신 반동기 복제를 선택하면 소스 서버와 리플리카 서버 사이의 동기화를 ‘어느 정도’는 보장할 수 있겠네요!
하지만 반동기 복제 또한 정확히 어느 시점에 이벤트를 리플리카 서버로 전송하고 응답을 받느냐에 따라 AFTER_SYNC, AFTER_COMMIT이라는 두 종류로 나눌 수 있었습니다.
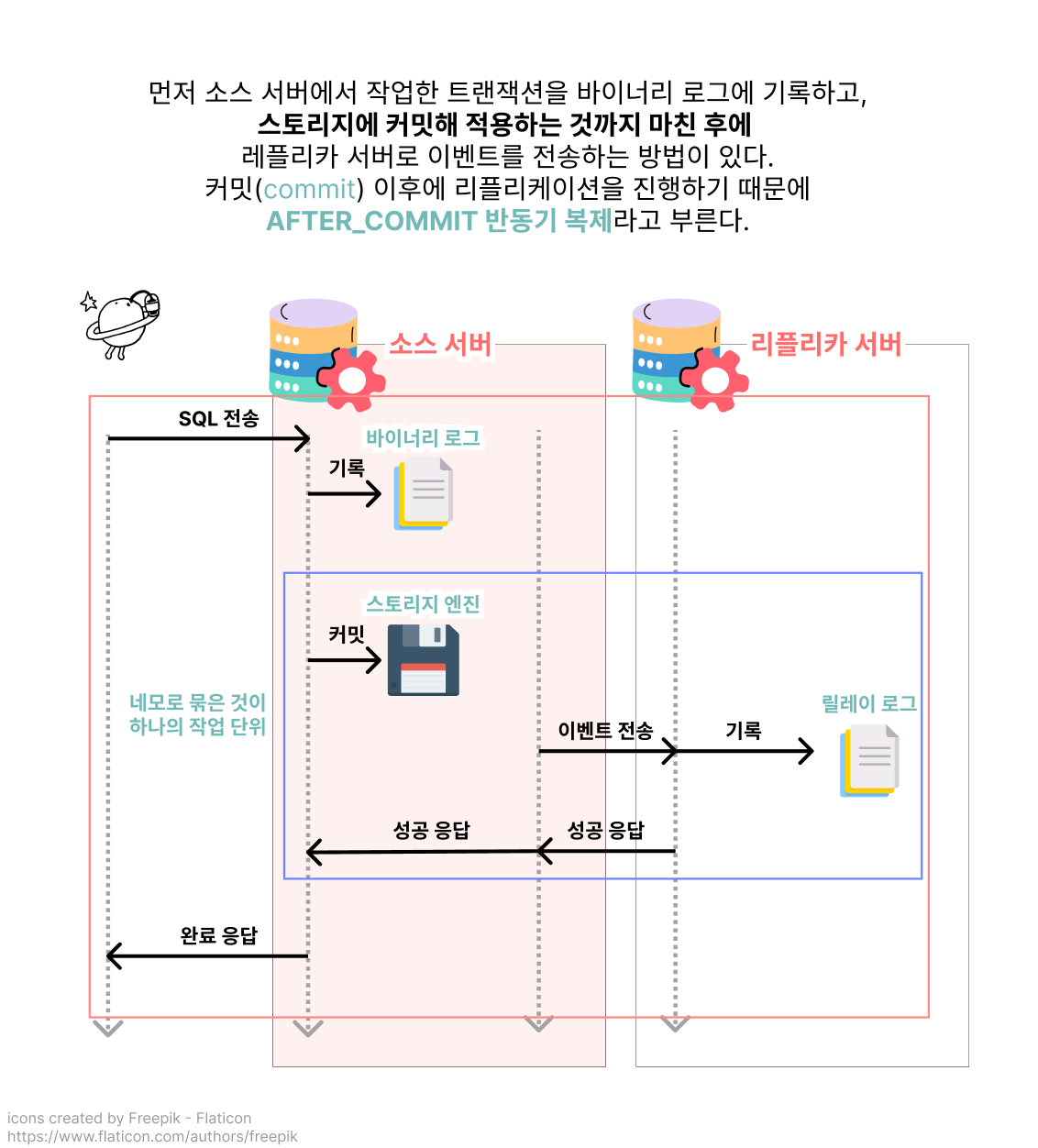
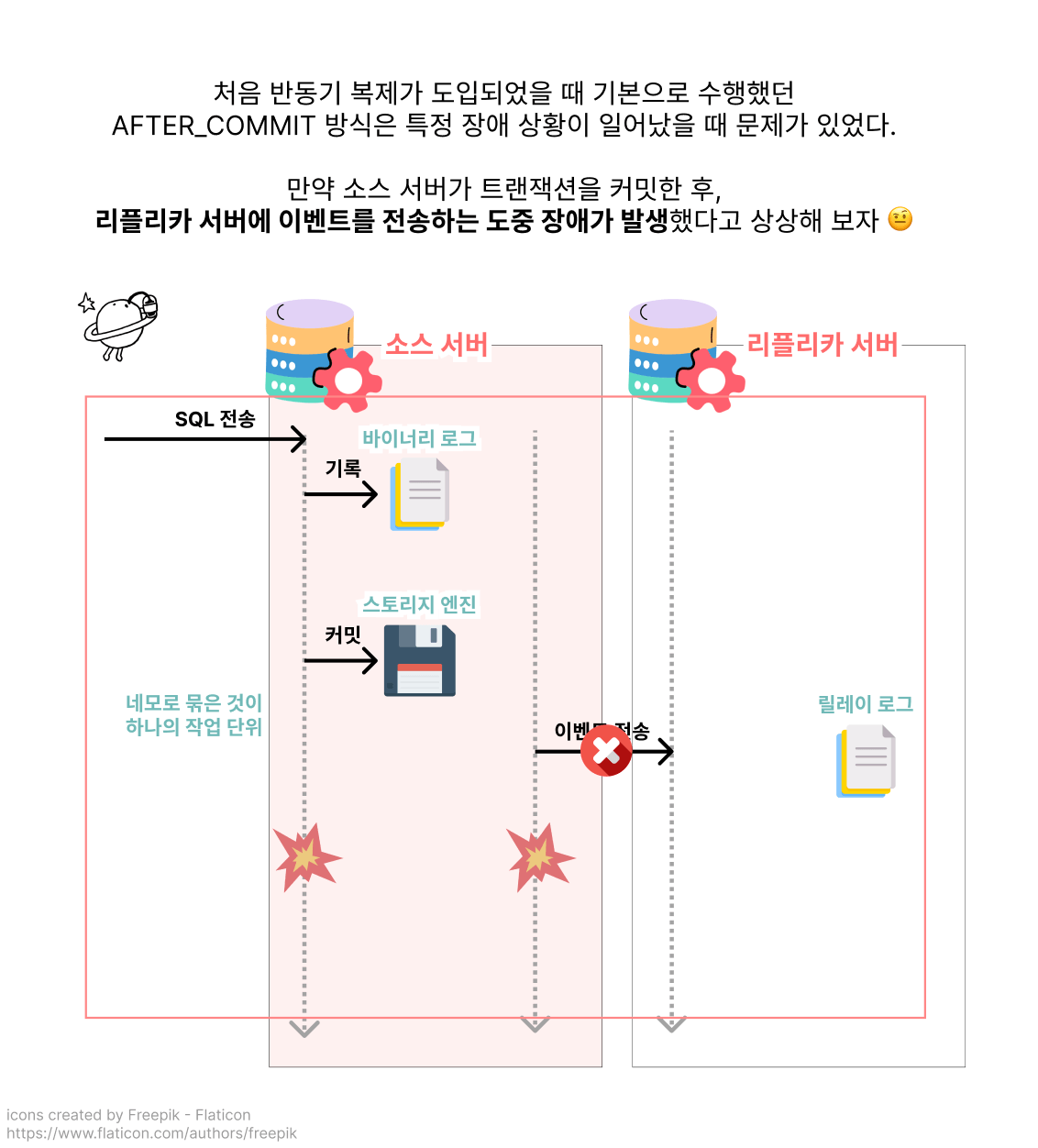
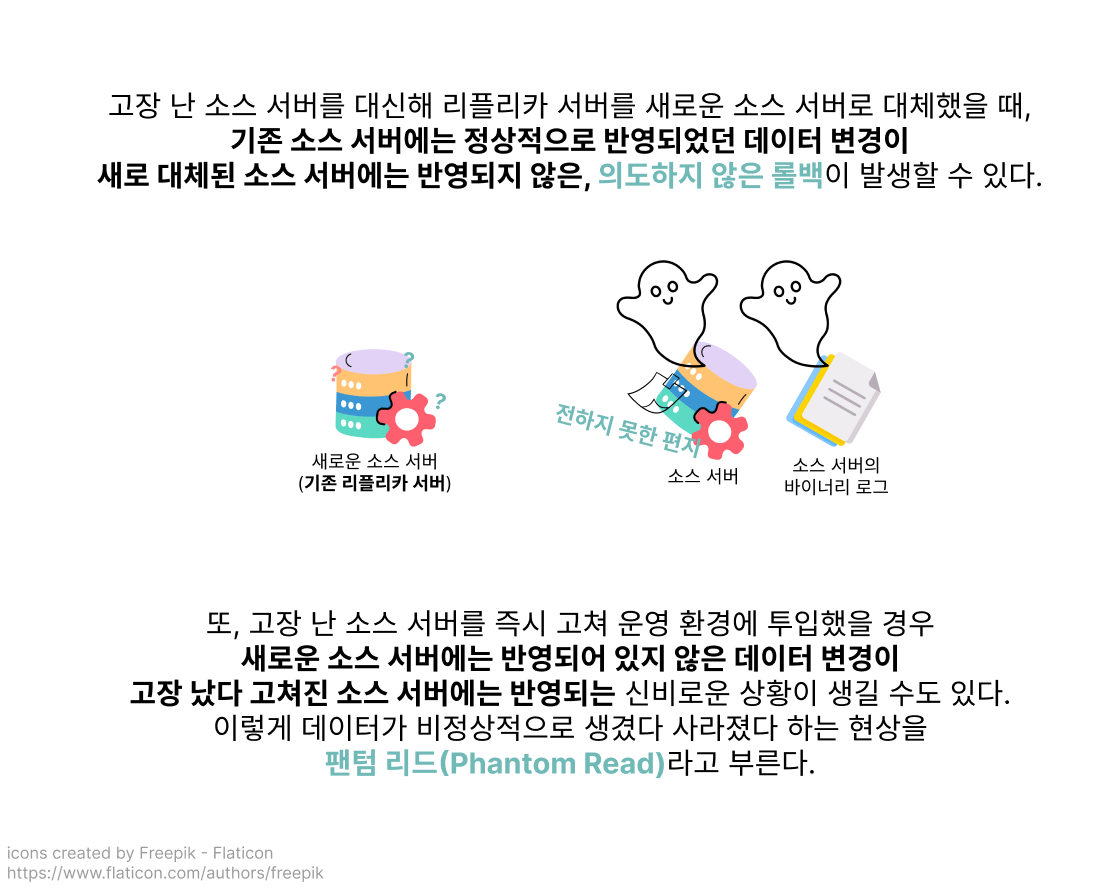
흔치 않은 장애 상황에서만 일어날 수 있는 문제이지만, 팬텀 리드와 같은 데이터 정합성 문제가 일어날 여지가 있는 방식이 AFTER_COMMIT이군요 🤨
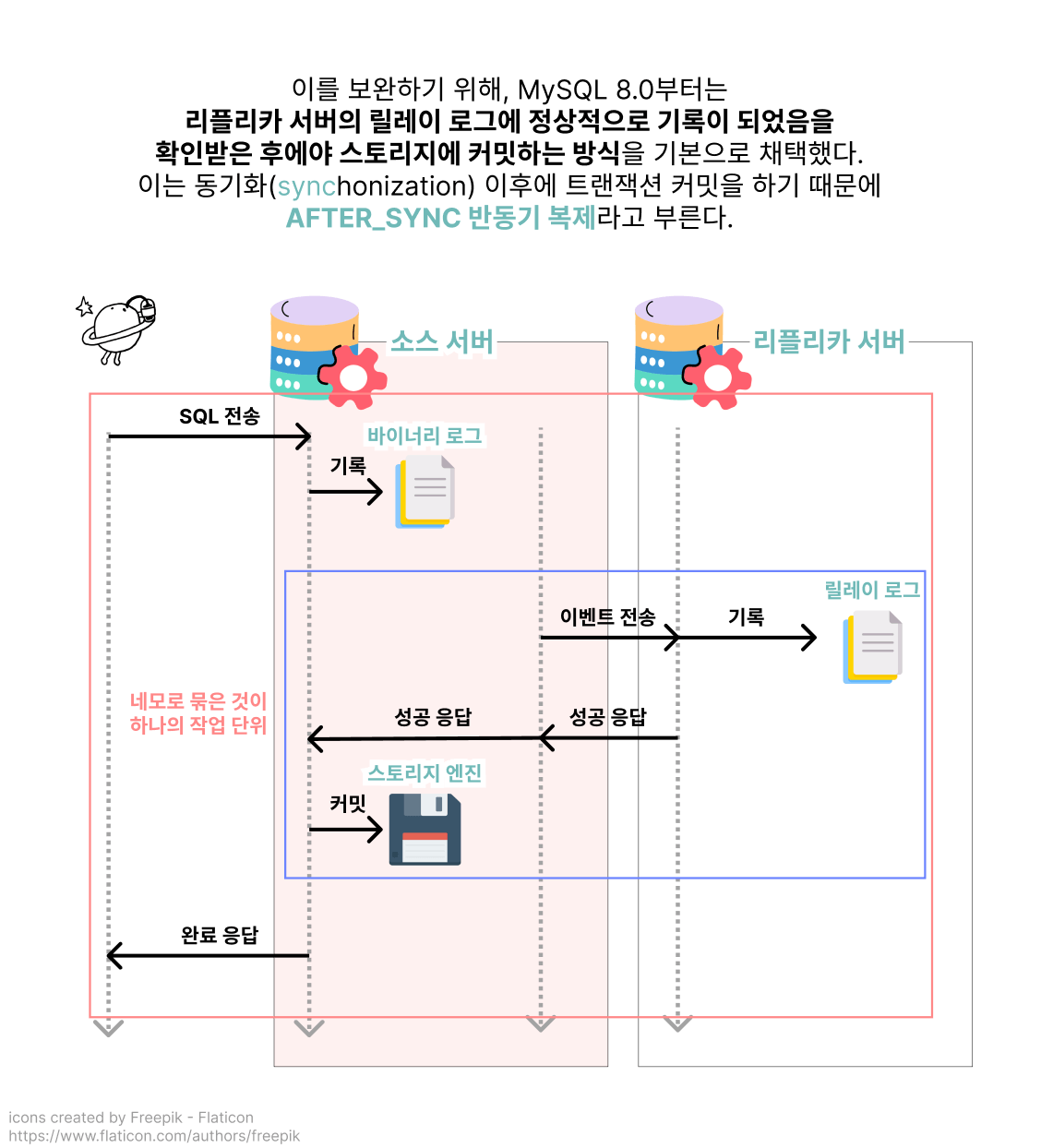
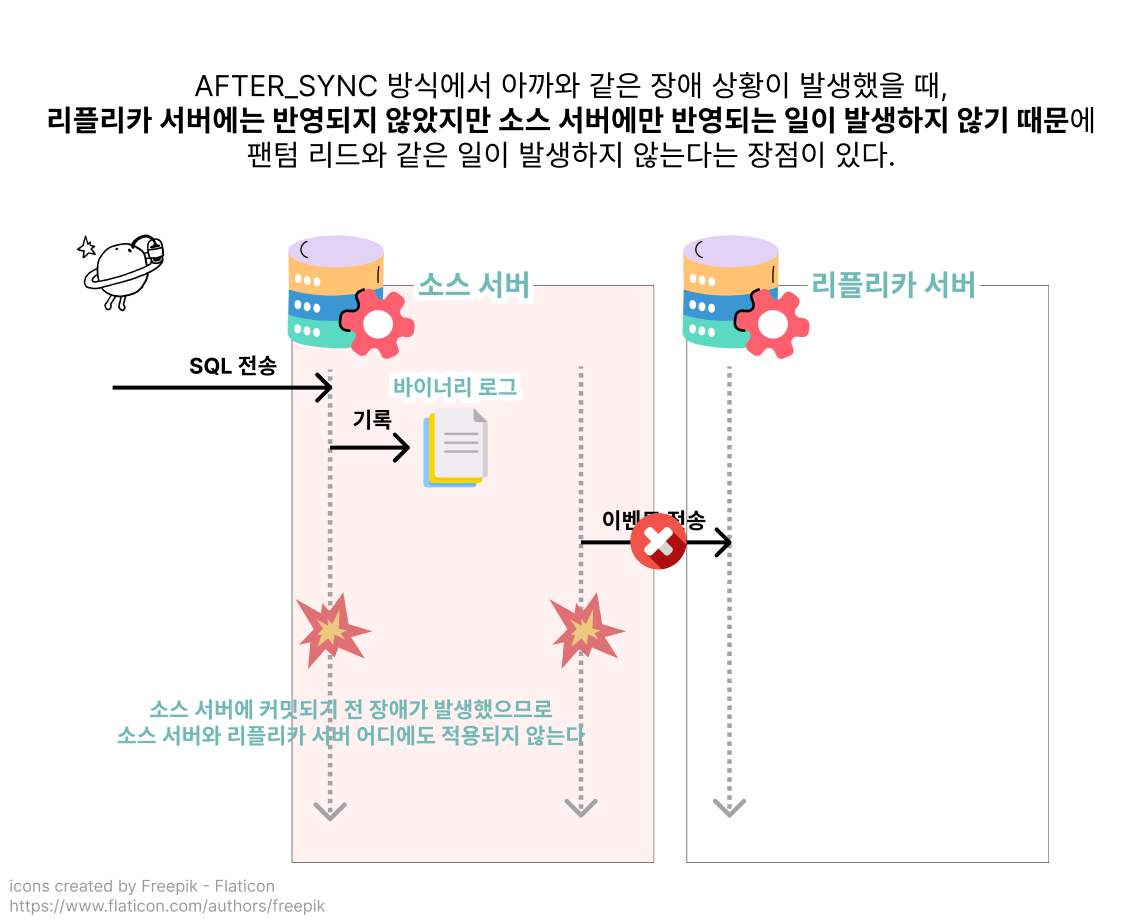
데이터의 정합성을 지키려면 AFTER_SYNC 방식의 반동기 복제를 적용하면 되겠다는 결론을 내린 테코. 반동기 복제 적용 방법이 MySQL 문서에 자세히 나와 있으니 그대로 따라 하기만 하면 되지만, 적용하기 전 마지막으로 진지하게 고민해 보기로 합니다. 데이터베이스의 속도를 내리면서까지 꼭 정합성을 지켜야만 할까?
성능과 정합성 사이의 줄다리기
‘사용자가 소스 서버에 쓰기 작업을 하고, 리플리카 서버에서 그 데이터를 읽으려 하면 데이터가 없을 수도 있잖아!’라고 생각한다면 데이터 정합성을 위해 반동기 방식을 쓰는 게 안전해 보이지만,
사실 데이터의 리플리케이션 작업은 우리의 생각보다 훨씬 짧은 시간 안에 이루어진다고 해요.

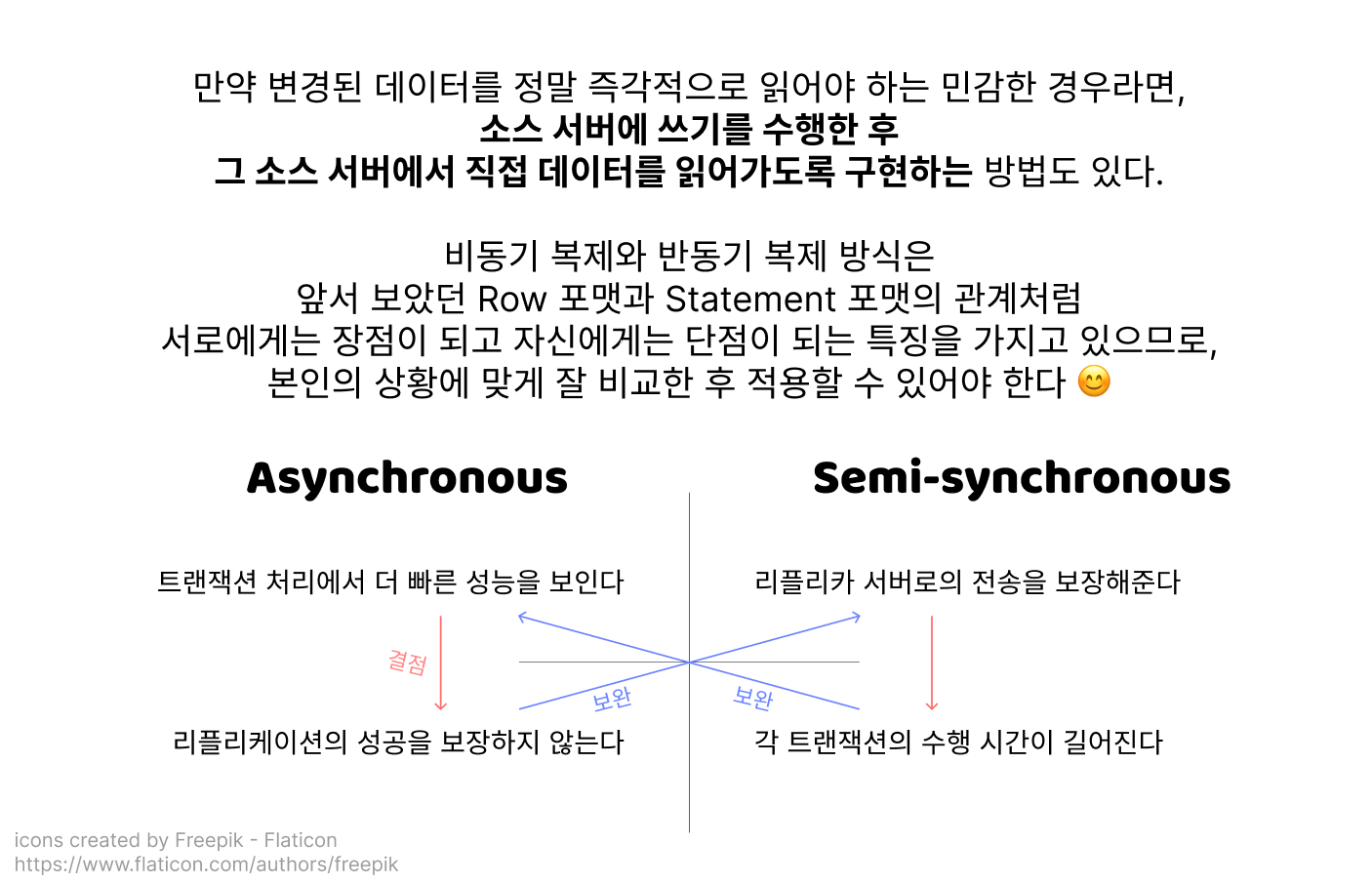
테코는 자신이 운영하는 카페의 성격을 되짚어 보았을 때, 비동기 복제 방식을 계속 쓴다고 하더라도 큰 불편이 일어날 일이 없으며 오히려 반동기 복제를 사용했을 때 데이터베이스의 작업 처리 속도가 느려져서 불편해할 사람들이 더 많겠구나! 라는 결론을 내렸어요.
그렇게 비동기 복제 방식을 계속 사용하기로 마음먹은 테코는 더 새롭고 좋은 기술이 있다고 해도 무조건 적용하기 전에 그것이 본인에게 꼭 필요한 기술인지 고민하는 것이 중요하다는 깨달음을 얻었습니다. 😊
요약
- MySQL 복제 동기화 방식
- 비동기
- 반동기
- 자료 Real MySQL 8.0 2권 pp.484~493
번외 - 리플리케이션 구조(토폴로지)
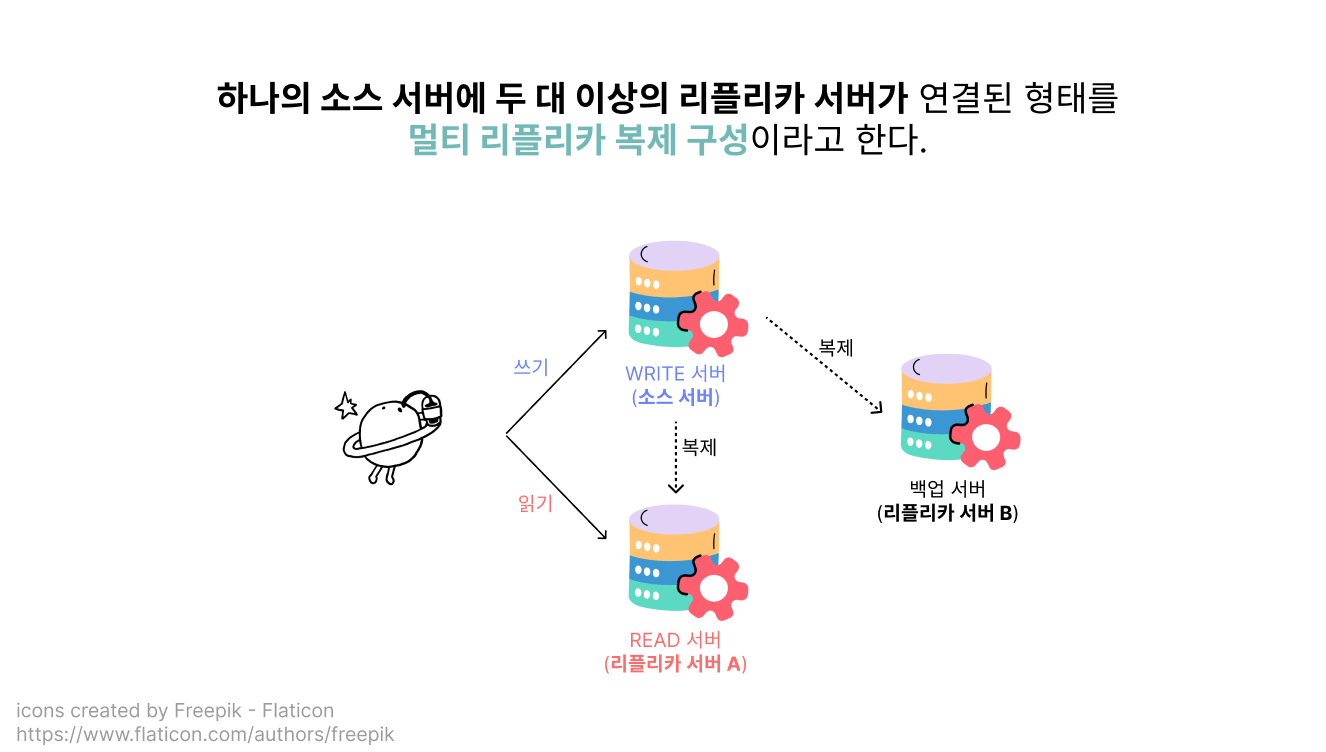
지금까지 리플리케이션을 설명하면서 예시로 들었던 테코네 카페 데이터베이스 설정은 소스 서버(쓰기용) + 리플리카 서버 1(읽기용) + 리플리카 서버 2(예비용) 이렇게 3대로 구성된 멀티 리플리카 복제 구성을 하고 있었습니다.
이런 멀티 리플리카 구성 외에도, 리플리케이션을 수행하는 목적에 따라 다양한 형�태로 데이터베이스들을 두고 운영할 수 있어요.
일반적으로 사용되는 데이터베이스 구성 방식들을 간단히 알아본 후 포스트를 마무리하겠습니다. 🐋
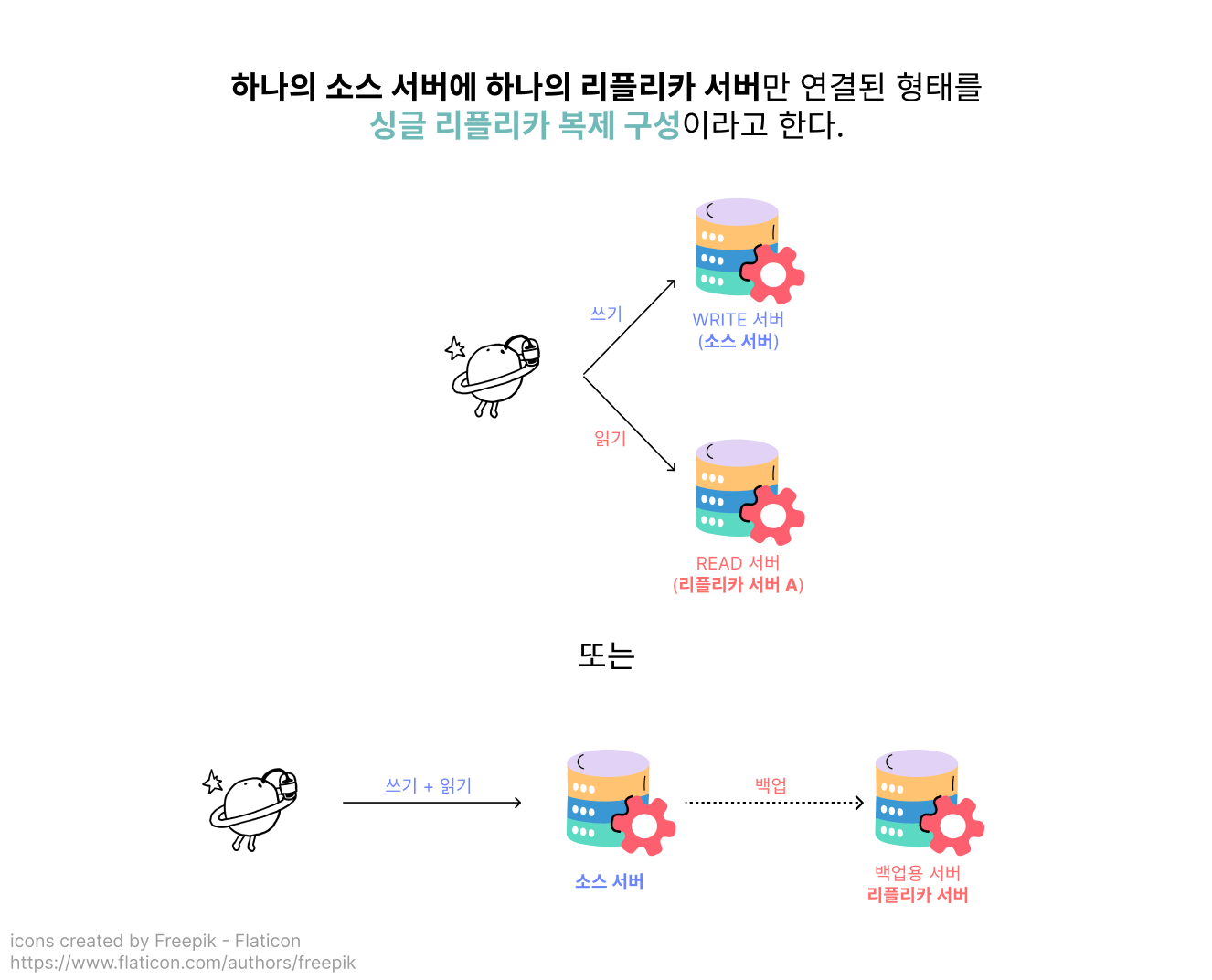
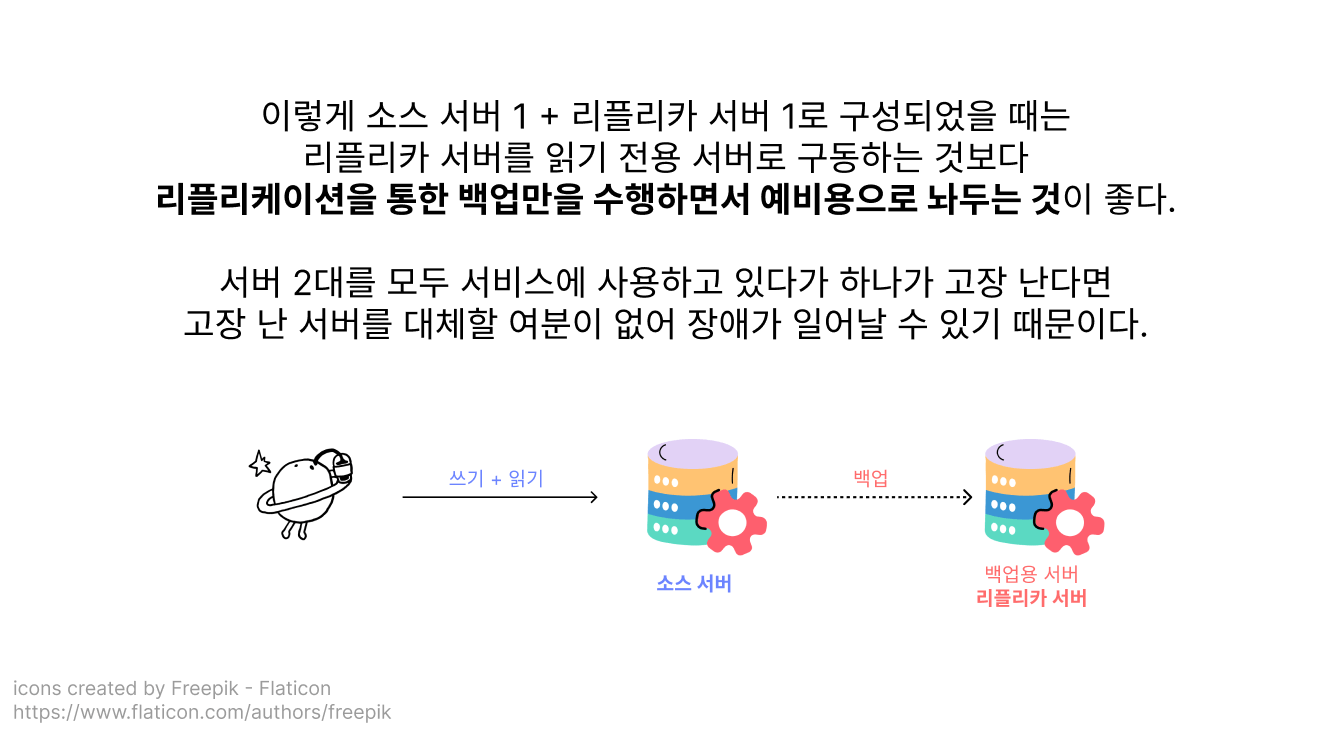
싱글 리플리카 복제 구성
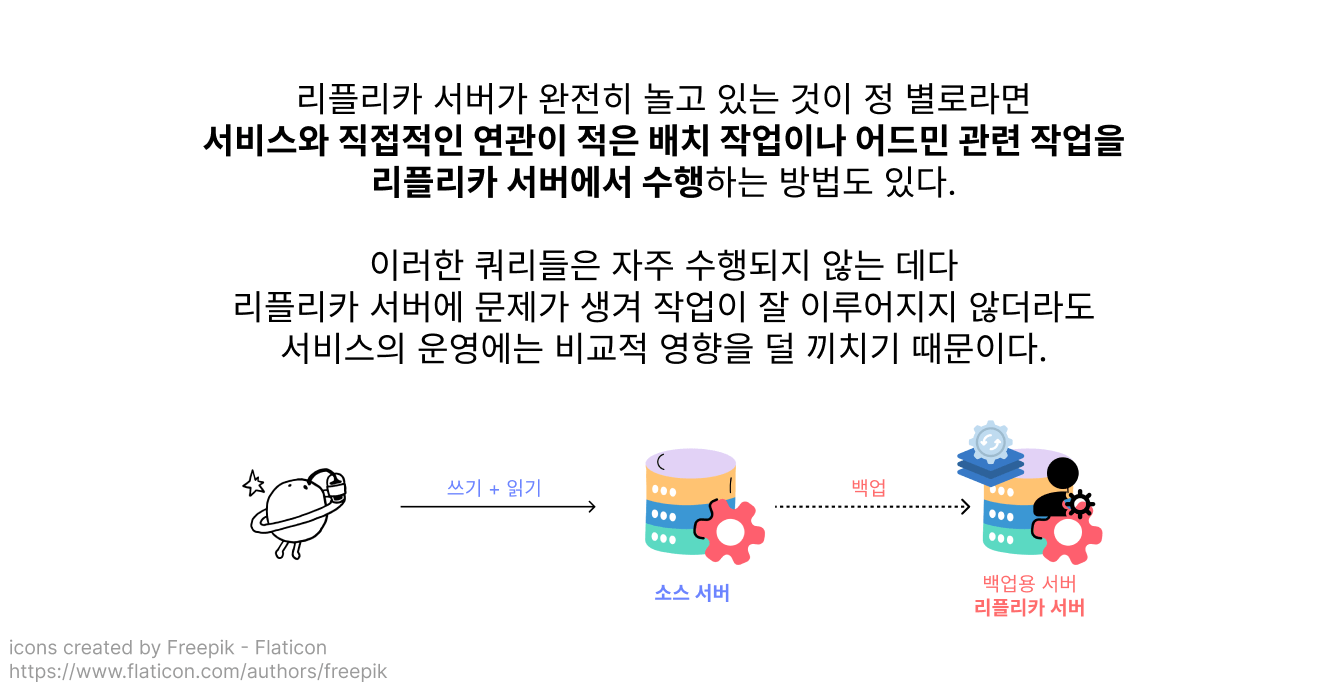
소스 서버 1 + 리플리카 서버 1로 구성된 가장 단순한 구성 방식을 싱글 리플리카 복제 구성이라고 불러요!
멀티 리플리카 복제 구성
싱글 리플리카 복제 구성에서, 다른 용도의 데이터베이스가 더 필요해서 여분의 리플리카 서버를 더 두기 시작한다면 멀티 리플리카 복제 구성이 돼요.
테코의 데이터베이스도 백업 용도 외에 읽기 작업을 수행하는 데이터베이스가 필요하게 되면서 멀티 리플리카 복제를 사용하게 됐었죠!



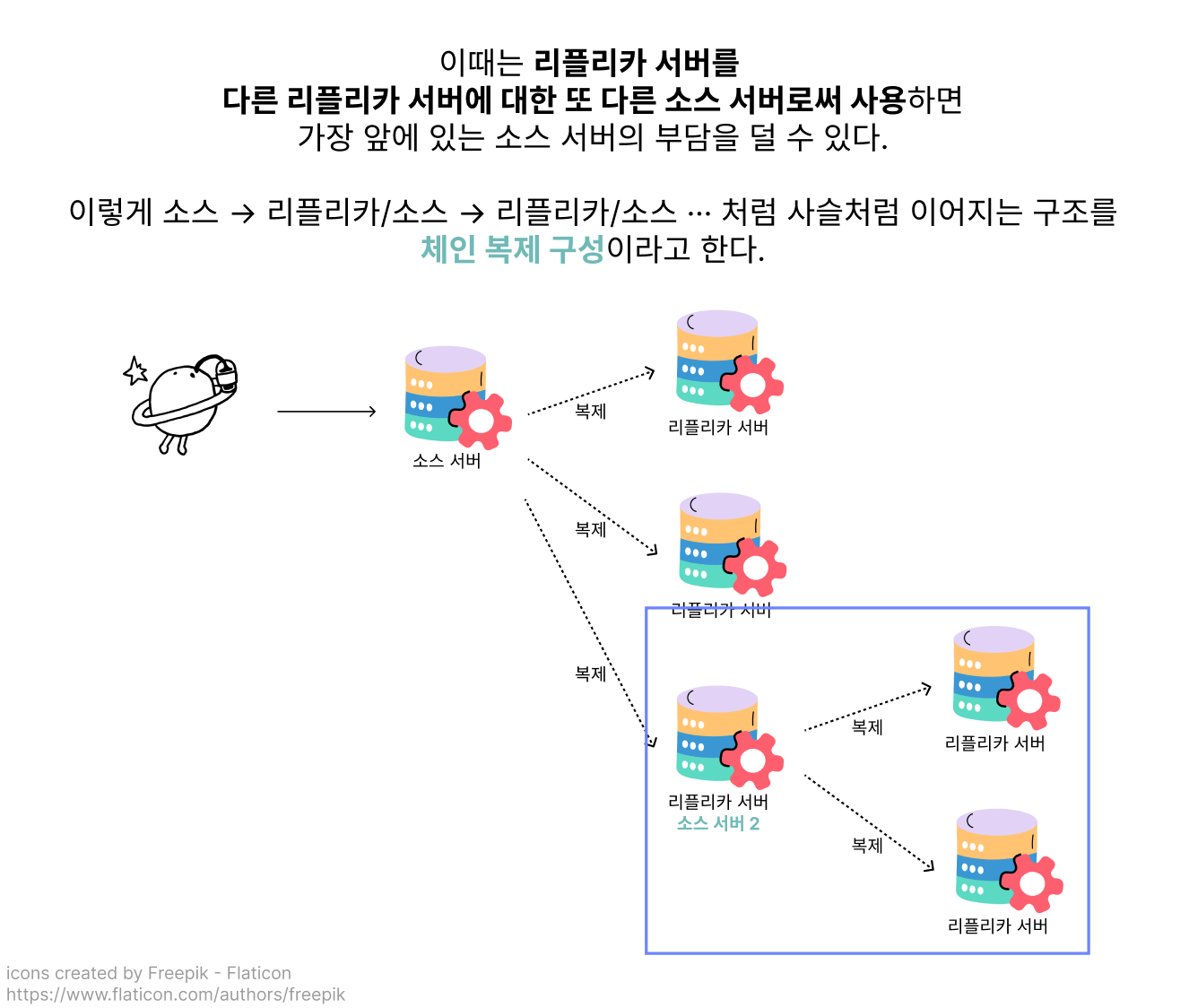
체인 복제 구성
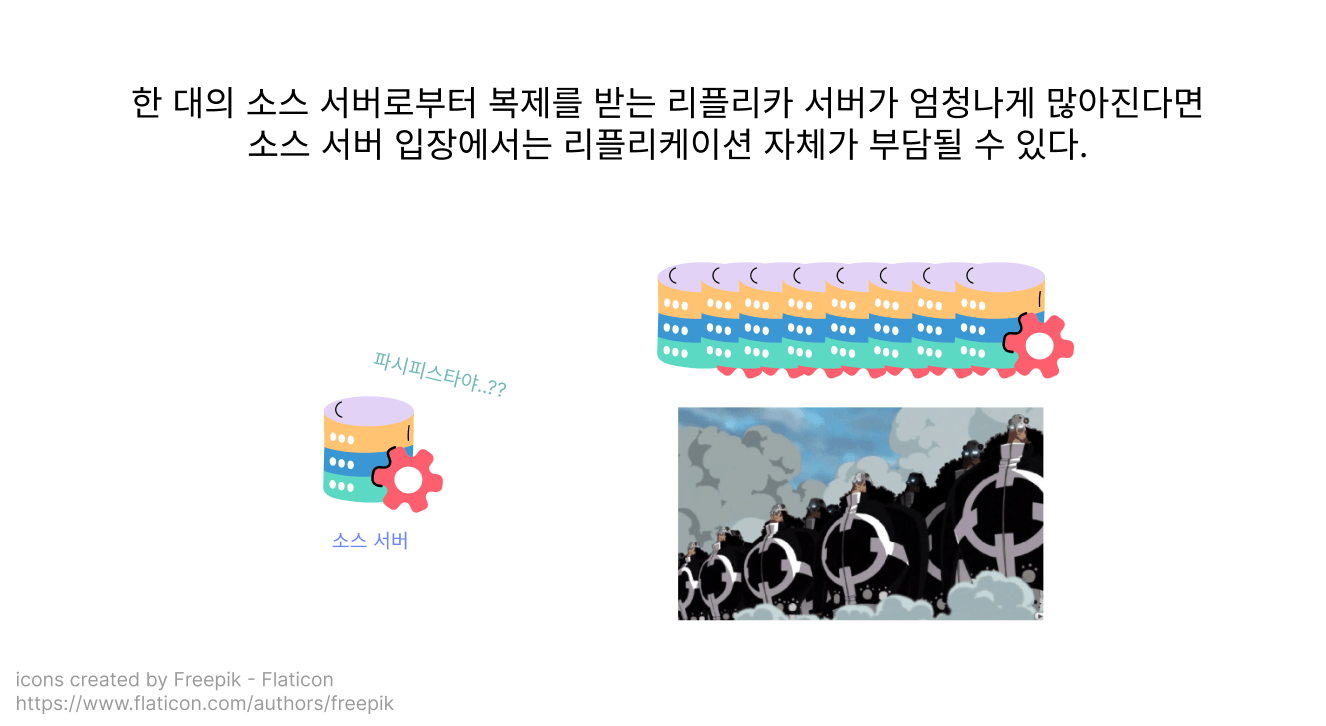
만약 소스 서버는 하나인데, 복제를 해주어야 하는 리플리카 서버가 엄청나게 많아진다면 어떻게 해야 할까요? 예를 들어, 대규모 서비스를 지탱하는 기술이라는 서적에서 예시로 든 하테나라는 기업은 데이터베이스 서버만 25대였다고 해요.
만약 이 기업의 리플리케이션 구성이 소스 서버 1대와 리플리카 서버 24대로 이루어졌다면, 소스 서버에서 리플리카 서버들로 이벤트를 전송하는 작업 자체가 부하로 작용할 수도 있을 거예요.
이때는 리플리카 서버가 또다시 다른 리플리카 서버에 대한 소스 서버 역할을 하는, 사슬같은 구조의 체인 복제 구성을 생각해볼 수 있습니다.
MySQL 서버를 전체적으로 업그레이드하거나, 장비를 일괄적으로 바꿀 때 복제 그룹 단위의 교체를 할 수 있는데요! 대략 아래와 같은 과정을 통해 교체가 이루어집니다.
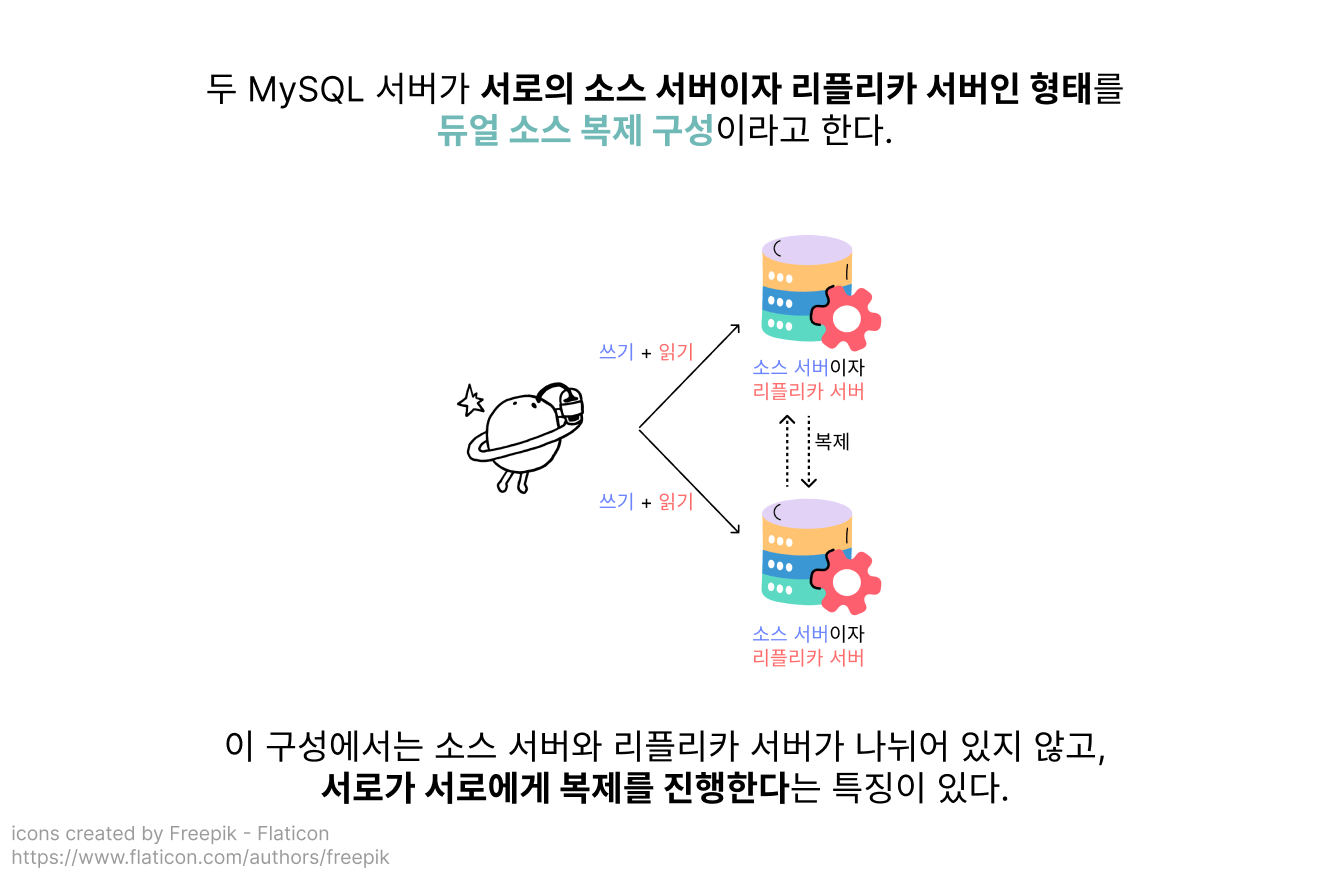
듀얼 소스 복제 구성
지금까지 알아본 복제 구성은 데이터 쓰기용 서버는 하나만 사용하고, 읽기용 서버만을 확장한다는 전제를 바탕으로 한 구성이었어요.
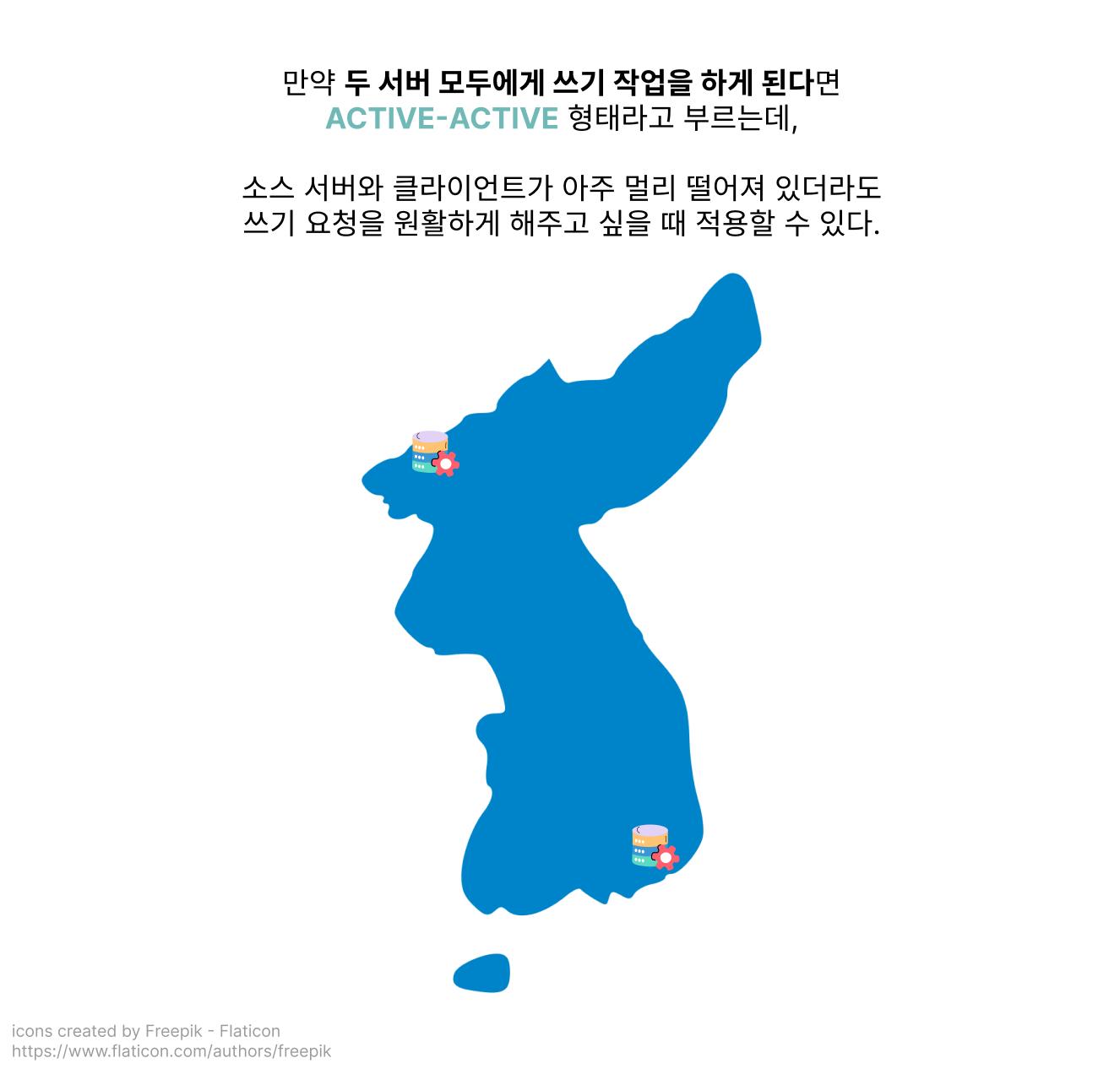
하지만 쓰기 작업을 아주 많이 하는 서비스인 경우에는 쓰기용 서버를 여러 개 두어야 할 수도 있습니다!

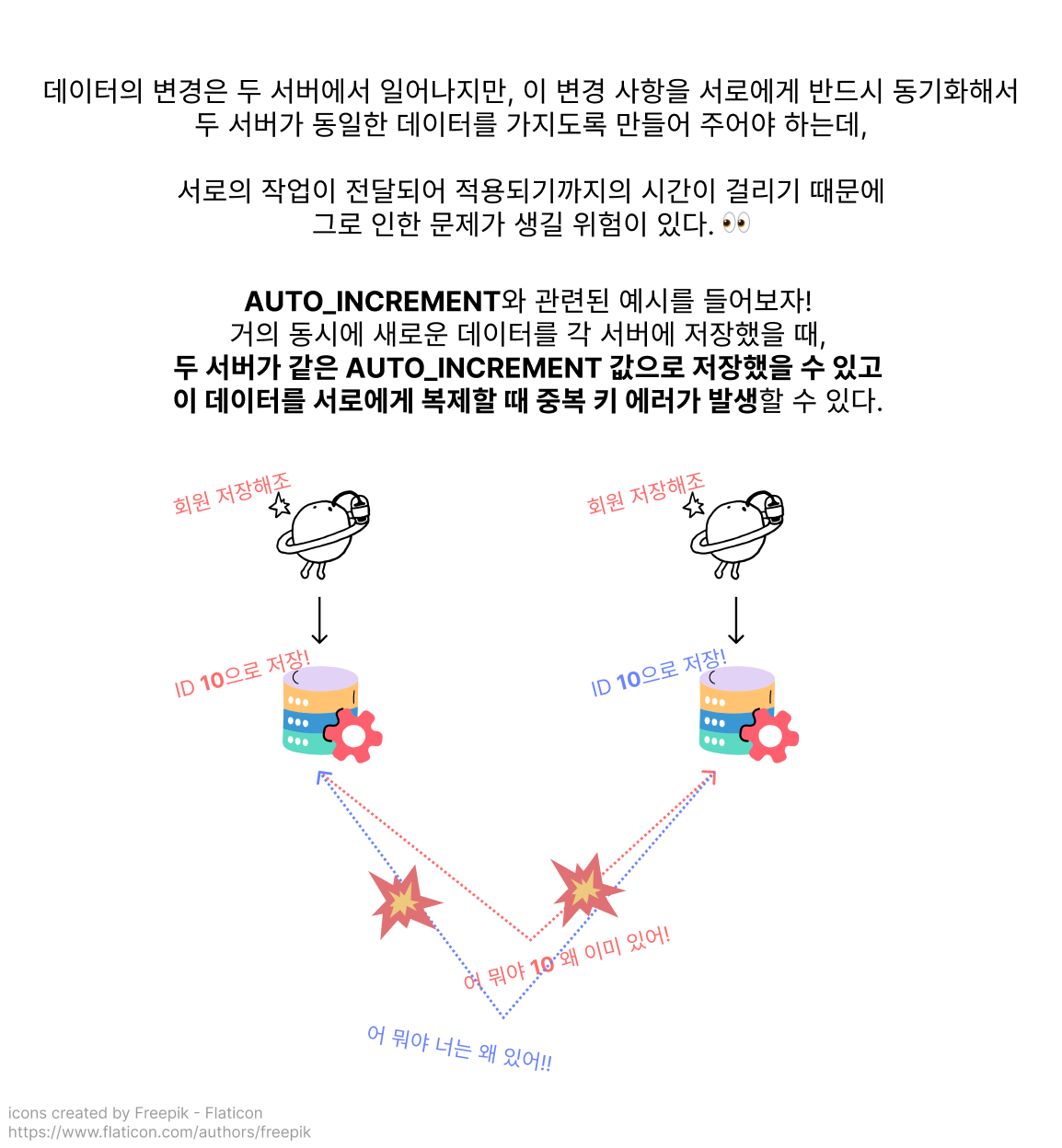
ACTIVE-PASSIVE와 ACTIVE-ACTIVE


요약
- MySQL 리플리케이션의 복제 토폴로지
- 싱글 리플리카 복제 구성
- 멀티 리플리카 복제 구성
- 체인 복제 구성
- 듀얼 소스 복제 구성
- 자료 Real MySQL 8.0 2권 pp.494~503
이렇게 테코네 카페의 시행착오를 따라가 보면서 데이터베이스, 그중에서도 MySQL의 리플리케이션 작업에 대해 알아보았습니다.
참고 자료로 활용한 Real MySQL 8.0 2권에 훨씬 자세한 내용이 기록되어 있으니 참고하시길 바라요!
읽어주셔서 고마워요. 테코도 이제 행복하게 살아야 한다! 🙌🏻🙌🏻🙌🏻
도움을 주신 분